Cum se calculează coeficientul de corelație în Excel. Testarea ipotezelor simple folosind testul chi-pătrat Pearson în MS EXCEL
Luați în considerare aplicația înDOMNIȘOARĂEXCELATestul chi-pătrat Pearson pentru testarea ipotezelor simple.
După obținerea datelor experimentale (adică când există unele probă) de obicei se face alegerea legii de distribuție care descrie cel mai bine variabila aleatoare reprezentată de un dat prelevarea de probe. Verificarea cât de bine sunt descrise datele experimentale de legea de distribuție teoretică selectată se realizează folosind criterii de acord. Ipoteza nulă, există de obicei o ipoteză despre egalitatea distribuției unei variabile aleatoare cu o lege teoretică.
Să ne uităm mai întâi la aplicație Testul de bunăstare a potrivirii lui Pearson X 2 (chi pătrat)în raport cu ipotezele simple (se consideră cunoscuţi parametrii distribuţiei teoretice). Apoi - , când este specificată doar forma distribuției și parametrii acestei distribuții și valoarea statistici X 2 sunt evaluate/calculate pe baza aceloraşi mostre.
Notă: În literatura de limba engleză, procedura de aplicare Testul Pearson de bunăstare a potrivirii X 2 are un nume Testul de bunătate a potrivirii chi-pătrat.
Să ne amintim procedura de testare a ipotezelor:
- bazat mostre valoarea este calculată statistici, care corespunde tipului de ipoteză testată. De exemplu, pentru folosit t-statistici(dacă nu se cunoaște);
- supus adevărului ipoteza nulă, distribuția acestuia statistici este cunoscut și poate fi folosit pentru a calcula probabilități (de exemplu, pentru t-statistici Acest );
- calculat pe baza mostre sens statistici comparat cu valoarea critică pentru o valoare dată ();
- ipoteza nulă respinge if value statistici mai mare decât critică (sau dacă probabilitatea de a obține această valoare statistici() Mai puțin nivelul de semnificație, care este o abordare echivalentă).
Să ducem la îndeplinire testarea ipotezelor pentru diverse distribuții.
Caz discret
Să presupunem că doi oameni joacă zaruri. Fiecare jucător are propriul său set de zaruri. Jucătorii aruncă pe rând 3 zaruri deodată. Fiecare rundă este câștigată de cel care are cele mai multe șase la un moment dat. Rezultatele sunt înregistrate. Unul dintre jucători, după 100 de runde, a avut bănuiala că zarurile adversarului său erau asimetrice, deoarece el câștigă adesea (de multe ori aruncă șase). El a decis să analizeze cât de probabil erau un asemenea număr de rezultate ale inamicilor.
Notă: Deoarece Sunt 3 cuburi, apoi poți rostogoli câte 0 o dată; 1; 2 sau 3 șase, adică o variabilă aleatoare poate lua 4 valori.
Din teoria probabilității știm că dacă zarurile sunt simetrice, atunci probabilitatea de a obține șase se supune. Prin urmare, după 100 de runde, frecvențele șase pot fi calculate folosind formula
=BINOM.DIST(A7,3,1/6,FALSE)*100
Formula presupune că în celulă A7 conține numărul corespunzător de șase aruncate într-o rundă.
Notă: Calculele sunt date în exemplu de fișier pe foaia Discrete.
Pentru comparație observat(Observat) și frecvențe teoretice(Așteptată) convenabil de utilizat.

Dacă frecvențele observate deviază semnificativ de la distribuția teoretică, ipoteza nulă despre distribuția unei variabile aleatoare conform unei legi teoretice ar trebui respinsă. Adică, dacă zarurile adversarului sunt asimetrice, atunci frecvențele observate vor fi „semnificativ diferite” de distribuție binomială.
În cazul nostru, la prima vedere, frecvențele sunt destul de apropiate și fără calcule este dificil să tragem o concluzie fără ambiguitate. Aplicabil Testul Pearson de bunăstare a potrivirii X 2, astfel încât în locul enunțului subiectiv „substanțial diferit”, care se poate face pe bază de comparație histogramelor, folosiți o afirmație corectă din punct de vedere matematic.
Folosim faptul că din cauza legea numerelor mari frecvența observată (Observată) cu creșterea volumului mostre n tinde către probabilitatea corespunzătoare legii teoretice (în cazul nostru, legea binomială). În cazul nostru, dimensiunea eșantionului n este 100.
Să vă prezentăm Test statistici, pe care îl notăm cu X 2:

unde O l este frecvența observată a evenimentelor pe care variabila aleatoare a luat anumite valori acceptabile, E l este frecvența teoretică corespunzătoare (Așteptată). L este numărul de valori pe care le poate lua o variabilă aleatoare (în cazul nostru este 4).
După cum se poate vedea din formulă, aceasta statistici este o măsură a proximității frecvențelor observate față de cele teoretice, adică poate fi folosit pentru a estima „distanțele” dintre aceste frecvențe. Dacă suma acestor „distanțe” este „prea mare”, atunci aceste frecvențe sunt „semnificativ diferite”. Este clar că dacă cubul nostru este simetric (adică aplicabil legea binomială), atunci probabilitatea ca suma „distanțelor” să fie „prea mare” va fi mică. Pentru a calcula această probabilitate trebuie să cunoaștem distribuția statistici X 2 ( statistici X 2 calculat pe baza aleatoriei mostre, prin urmare este o variabilă aleatoare și, prin urmare, are propria sa distribuția probabilității).
Din analogul multidimensional Teorema integrală Moivre-Laplace se ştie că pentru n->∞ variabila noastră aleatoare X 2 este asimptotic cu L - 1 grade de libertate.
Deci, dacă valoarea calculată statistici X 2 (suma „distanțelor” dintre frecvențe) va fi mai mare decât o anumită valoare limită, atunci vom avea motive să respingem ipoteza nulă. La fel ca verificarea ipoteze parametrice, valoarea limită este setată prin nivelul de semnificație. Dacă probabilitatea ca statistica X 2 să ia o valoare mai mică sau egală cu cea calculată ( p-sens), va fi mai puțin nivelul de semnificație, Acea ipoteza nulă poate fi respins.
În cazul nostru, valoarea statistică este 22.757. Probabilitatea ca statistica X2 să ia o valoare mai mare sau egală cu 22,757 este foarte mică (0,000045) și poate fi calculată folosind formulele
=CHI2.DIST.PH(22.757,4-1) sau
=CHI2.TEST(Observat; Așteptat)
Notă: Funcția CHI2.TEST() este concepută special pentru a testa relația dintre două variabile categoriale (vezi).
Probabilitatea 0,000045 este semnificativ mai mică decât de obicei nivelul de semnificație 0,05. Deci, jucătorul are toate motivele să-și suspecteze adversarul de necinste ( ipoteza nulă i se refuză onestitatea).

Atunci când se utilizează criteriul X 2 este necesar să se asigure că volumul mostre n a fost suficient de mare, altfel aproximarea distribuției nu ar fi valabilă statistica X 2. De obicei, se crede că pentru aceasta este suficient ca frecvențele observate (Observate) să fie mai mari decât 5. Dacă nu este cazul, atunci frecvențele mici sunt combinate într-una sau adăugate la alte frecvențe, iar valorii combinate i se atribuie un total. probabilitatea și, în consecință, numărul de grade de libertate este redus X 2 distribuții.
Pentru a îmbunătăți calitatea aplicării criteriul X 2(), este necesar să se reducă intervalele de partiție (mărește L și, în consecință, crește numărul grade de libertate), totuși, acest lucru este împiedicat de limitarea numărului de observații incluse în fiecare interval (db>5).
Caz continuu
Testul Pearson de bunăstare a potrivirii X 2 se poate aplica si in cazul .
Să luăm în considerare un anumit probă, format din 200 de valori. Ipoteza nulă afirmă că probă făcut din .
Notă: variabile aleatorii în exemplu de fișier pe foaia Continuă generate folosind formula =NORM.ST.INV(RAND()). Prin urmare, noi valori mostre sunt generate de fiecare dată când foaia este recalculată.
Dacă setul de date existent este adecvat, poate fi evaluat vizual.

După cum se poate vedea din diagramă, valorile eșantionului se potrivesc destul de bine de-a lungul liniei drepte. Cu toate acestea, ca și pentru testarea ipotezelor aplicabil Testul de bună potrivire Pearson X 2.
Pentru a face acest lucru, împărțim intervalul de modificare a variabilei aleatoare în intervale cu un pas de 0,5. Să calculăm frecvențele observate și teoretice. Calculăm frecvențele observate folosind funcția FREQUENCY(), iar cele teoretice folosind funcția NORM.ST.DIST().
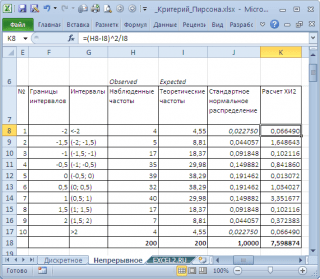
Notă: La fel ca pentru caz discret, este necesar să se asigure că probă a fost destul de mare, iar intervalul a inclus >5 valori.
Să calculăm statistica X2 și să o comparăm cu valoarea critică pentru un anumit nivelul de semnificație(0,05). Deoarece am împărțit intervalul de modificare a unei variabile aleatoare în 10 intervale, apoi numărul de grade de libertate este 9. Valoarea critică poate fi calculată folosind formula
=CHI2.OBR.PH(0,05;9) sau
=CHI2.OBR(1-0,05;9)
Graficul de mai sus arată că valoarea statistică este 8,19, care este semnificativ mai mare valoare critica – ipoteza nulă nu este respins.
Mai jos este unde probă a căpătat o semnificaţie improbabilă şi se bazează pe criteriu Consimțământul Pearson X 2 ipoteza nulă a fost respinsă (chiar dacă valorile aleatorii au fost generate folosind formula =NORM.ST.INV(RAND()), furnizarea probă din distribuție normală standard).

Ipoteza nulă respins, deși vizual datele sunt situate destul de aproape de o linie dreaptă.
Să luăm și ca exemplu probă de la U(-3; 3). În acest caz, chiar și din grafic este evident că ipoteza nulă ar trebui respins.

Criteriu Consimțământul Pearson X 2 confirmă de asemenea că ipoteza nulă ar trebui respins.
Sarcina 1.
Folosind testul Pearson, la un nivel de semnificație A= 0,05 verificați dacă ipoteza despre distribuția normală a populației este consecventă X cu distribuția empirică a mărimii eșantionului n = 200.
Soluţie.
1. Să calculăm  și abaterea standard a eșantionului
și abaterea standard a eșantionului ![]() .
.
2. Să calculăm frecvențele teoretice, ținând cont de faptul că n = 200, h= 2, = 4,695, conform formulei  .
.
Să creăm un tabel de calcul (valorile funcției j(X) sunt date în Anexa 1).
i |
||||
3. Să comparăm frecvențele empirice și teoretice. Să alcătuim un tabel de calcul din care vom găsi valoarea observată a criteriului  :
:
i |
|||||
| Sumă |
Conform tabelului punctelor critice de distribuție (Anexa 6), pe nivel de semnificație A= 0,05 și numărul de grade de libertate k = s– 3 = 9 – 3 = 6 găsim punctul critic al regiunii critice din dreapta (0,05; 6) = 12,6.
Deoarece =22,2 > = 12,6, respingem ipoteza despre distribuția normală a populației. Cu alte cuvinte, frecvențele empirice și teoretice diferă semnificativ.
Problema 2
Sunt prezentate date statistice.
Rezultate măsurarea diametrului n= 200 role după măcinare sunt rezumate în tabel. (mm):
Masa Seria de variație de frecvență a diametrelor rolei
| i | ||||||||
xi, mm |
||||||||
xi, mm |
||||||||
Necesar:
1) alcătuiește o serie de variații discrete, ordonând-o dacă este necesar;
2) determinarea principalelor caracteristici numerice ale seriei;
3) dați o reprezentare grafică a seriei sub forma unui poligon de distribuție (histogramă);
4) construiți o curbă de distribuție normală teoretică și verificați corespondența distribuțiilor empirice și teoretice folosind criteriul Pearson. Când testați ipoteza statistică despre tipul de distribuție, acceptați nivelul de semnificație a = 0,05
Soluţie:
Vom găsi prin definiție principalele caracteristici numerice ale unei serii de variații date. Diametrul mediu al rolelor este (mm):
X medie = = 6,753;
dispersie corectată (mm2):
D = ![]() = 0,0009166;
= 0,0009166;
abatere pătrată medie corectată (standard) (mm):
s = = 0,03028.
Orez. Distribuția de frecvență a diametrelor rolelor
Distribuția de frecvență inițială („brută”) a seriei de variații, de ex. corespondenţă ni(xi), se remarcă printr-o răspândire destul de mare a valorilor ni relativ la o curbă ipotetică de „medie” (Fig.). În acest caz, este de preferat să se construiască și să se analizeze o serie de variații de interval, combinând frecvențele pentru diametrele care se încadrează în intervalele corespunzătoare.
Numărul de grupuri de intervale K Să o definim folosind formula Sturgess:
K= 1 + log2 n= 1 + 3,322 lg n,
Unde n= 200 – dimensiunea eșantionului. În cazul nostru
K= 1 + 3,322×lg200 = 1 + 3,322×2,301 = 8,644 » 8.
Lățimea intervalului este (6,83 – 6,68)/8 = 0,01875 » 0,02 mm.
Seria de variații de interval este prezentată în tabel.
Tabel Seria de variație a intervalului de frecvență a diametrelor rolei.
| k | ||||||||
xk, mm |
||||||||
O serie de intervale poate fi prezentată vizual sub forma unei histograme a distribuției frecvenței. 
Orez. Distribuția de frecvență a diametrelor rolelor. Linia continuă este o curbă normală de netezire.
Apariția histogramei ne permite să facem ipoteza că distribuția diametrelor rolelor respectă legea normală, conform căreia frecvențele teoretice pot fi găsite ca
nk, teorie = n× N(A; s; xk)×D xk,
unde, la rândul său, curba Gaussiană de netezire a distribuției normale este determinată de expresia:
N(A; s; xk) =  .
.
În aceste expresii xk– centrele intervalelor din seria de variație a intervalului de frecvență.
De exemplu, X 1 = (6,68 + 6,70)/2 = 6,69. Ca evaluări de centru A iar parametrul s al curbei Gaussiene poate fi luat:
A = X mier
Din fig. se poate observa că curba de distribuție normală Gaussiană corespunde în general distribuției empirice a intervalului. Cu toate acestea, ar trebui să se verifice semnificația statistică a acestei corespondențe. Pentru a verifica corespondența distribuției empirice cu distribuția empirică, folosim criteriul Pearson de bunătate de potrivire c2. Pentru a face acest lucru, calculați valoarea empirică a criteriului ca sumă
=  ,
,
Unde nkȘi nk,teor – frecvențe empirice și, respectiv, teoretice (normale). Este convenabil să prezentați rezultatele calculului în formă tabelară:
Masa Calculele testului Pearson
[xk, xk+ 1), mm |
xk, mm |
nk,teor |
||
Vom găsi valoarea critică a criteriului folosind tabelul Pearson pentru nivelul de semnificație a = 0,05 și numărul de grade de libertate d.f. = K – 1 – r, Unde K= 8 – numărul de intervale ale seriei de variații de interval; r= 2 – numărul de parametri ai distribuției teoretice estimați pe baza datelor eșantionului (în acest caz, parametrii Ași s). Prin urmare, d.f. = 5. Valoarea critică a criteriului Pearson este crit(a; d.f.) = 11,1. Din moment ce c2emp< c2крит, заключаем, что согласие между эмпирическим и теоретическим нормальным распределением является статистическим значимым. Иными словами, теоретическое нормальное распределение удовлетворительно описывает эмпирические данные.
Problema 3
Cutiile de ciocolată sunt ambalate automat. Conform schemei de eșantionare aleatorie nerepetitivă, au fost prelevate 130 din cele 2000 de pachete conținute în lot și s-au obținut următoarele date privind greutatea acestora:
Este necesar să se utilizeze criteriul Pearson la un nivel de semnificație de a=0,05 pentru a testa ipoteza că variabila aleatoare X - greutatea pachetelor - este distribuită conform legii normale. Construiți o histogramă a distribuției empirice și a curbei normale corespunzătoare pe un grafic.
Soluţie
1012,5
= 615,3846
Notă:
În principiu, varianța eșantionului corectată ar trebui luată ca varianță a legii distribuției normale. Dar pentru că numărul de observații - 130 este suficient de mare, atunci cel „obișnuit” va face.
Astfel, distribuția normală teoretică este:

[xi ; xi+1]
Frecvențele empirice
niProbabilități
pi
Frecvențe teoretice
npi
(ni-npi)2
Coeficientul de corelație reflectă gradul de relație dintre doi indicatori. Ia întotdeauna o valoare de la -1 la 1. Dacă coeficientul este situat în jurul valorii de 0, atunci nu există nicio legătură între variabile.
Dacă valoarea este aproape de unu (de la 0,9, de exemplu), atunci există o relație directă puternică între obiectele observate. Dacă coeficientul este aproape de celălalt punct extrem al intervalului (-1), atunci există o relație inversă puternică între variabile. Când valoarea este undeva între 0 la 1 sau 0 la -1, atunci vorbim de o conexiune slabă (directă sau inversă). De obicei, această relație nu este luată în considerare: se crede că nu există.
Calculul coeficientului de corelare în Excel
Să ne uităm la un exemplu de metode de calcul al coeficientului de corelație, caracteristici ale relațiilor directe și inverse între variabile.
Valorile indicatorilor x și y:
Y este o variabilă independentă, x este o variabilă dependentă. Este necesar să se găsească puterea (puternic/slab) și direcția (înainte/invers) conexiunii dintre ele. Formula coeficientului de corelație arată astfel:

Pentru a fi mai ușor de înțeles, să-l împărțim în câteva elemente simple.


Între variabile se determină o relație directă puternică.
Funcția CORREL încorporată evită calculele complexe. Să calculăm coeficientul de corelație de pereche în Excel folosindu-l. Apelați vrăjitorul de funcție. Îl găsim pe cel de care avem nevoie. Argumentele funcției sunt o matrice de valori y și o matrice de valori x:

Să arătăm valorile variabilelor pe grafic:

O conexiune puternică între y și x este vizibilă, deoarece liniile sunt aproape paralele între ele. Relația este directă: y crește - x crește, y scade - x scade.
Matricea coeficientului de corelație perechi în Excel
Matricea de corelație este un tabel la intersecția rândurilor și coloanelor din care se află coeficienții de corelație între valorile corespunzătoare. Este logic să-l construiți pentru mai multe variabile.

Matricea coeficienților de corelație în Excel este construită cu ajutorul instrumentului „Corelație” din pachetul „Analiza datelor”.


S-a găsit o relație directă puternică între valorile lui y și x1. Există un feedback puternic între x1 și x2. Practic nu există nicio legătură cu valorile din coloana x3.
1.Deschideți Excel
2.Creați coloane de date. În exemplul nostru, vom lua în considerare relația, sau corelația, dintre agresivitate și îndoiala de sine la elevii de clasa întâi. La experiment au participat 30 de copii, datele sunt prezentate în tabelul Excel:
1 coloană - numărul subiectului
2 coloana - agresivitateîn puncte
3 coloana - neîncredereaîn puncte
3. Apoi trebuie să selectați o celulă goală de lângă tabel și să faceți clic pe pictogramă f(x)în panoul Excel

4. Se va deschide meniul de funcții, trebuie să selectați dintre categorii Statistic , iar apoi printre lista de funcții găsiți în ordine alfabetică CORRELși faceți clic pe OK

5.Apoi se va deschide un meniu cu argumente ale funcției, care vă va permite să selectați coloanele de date de care avem nevoie. Pentru a selecta prima coloană Agresivitate trebuie să faceți clic pe butonul albastru de lângă linie Matrice1

6.Selectați datele pentru Matrice1 din coloană Agresivitateși faceți clic pe butonul albastru din caseta de dialog

7. Apoi, similar cu Array 1, faceți clic pe butonul albastru de lângă linie Matrice 2

8.Selectați datele pentru Matrice 2- coloana Dificultateși apăsați din nou butonul albastru, apoi OK

9. Aici, coeficientul de corelație r-Pearson a fost calculat și scris în celula selectată. În cazul nostru, este pozitiv și aproximativ egal cu 0,225 . Aceasta vorbește despre pozitiv moderat legături între agresivitate și îndoială de sine la elevii de clasa întâi

Prin urmare, inferență statistică experimentul va fi: r = 0,225, s-a relevat o relație pozitivă moderată între variabile agresivitateȘi neîncrederea.
Unele studii necesită specificarea nivelului p de semnificație al coeficientului de corelație, dar Excel, spre deosebire de SPSS, nu oferă această opțiune. E în regulă, există (A.D. Nasledov).
De asemenea, îl puteți atașa la rezultatele cercetării.

Articolul de astăzi va vorbi despre modul în care variabilele pot fi legate între ele. Folosind corelația, putem determina dacă există o relație între prima și a doua variabilă. Sper că veți găsi această activitate la fel de distractivă ca și precedentele!
Corelația măsoară puterea și direcția relației dintre x și y. Figura prezintă diferite tipuri de corelații sub formă de diagrame de dispersie de perechi ordonate (x, y). În mod tradițional, variabila x este plasată pe axa orizontală, iar variabila y pe axa verticală.

Graficul A este un exemplu de corelație liniară pozitivă: pe măsură ce x crește, și crește și liniar. Graficul B ne arată un exemplu de corelație liniară negativă, unde pe măsură ce x crește, y scade liniar. În graficul C vedem că nu există o corelație între x și y. Aceste variabile nu se influențează reciproc în niciun fel.
În cele din urmă, Graficul D este un exemplu de relații neliniare între variabile. Pe măsură ce x crește, y mai întâi scade, apoi își schimbă direcția și crește.
Restul articolului se concentrează pe relațiile liniare dintre variabilele dependente și independente.
Coeficient de corelație
Coeficientul de corelație, r, ne oferă atât puterea, cât și direcția relației dintre variabilele independente și dependente. Valorile lui r variază între -1,0 și +1,0. Când r este pozitiv, relația dintre x și y este pozitivă (graficul A din figură), iar când r este negativ, relația este și negativă (graficul B). Un coeficient de corelație apropiat de zero indică faptul că nu există nicio relație între x și y (graficul C).
Forța relației dintre x și y este determinată de faptul dacă coeficientul de corelație este aproape de - 1,0 sau +- 1,0. Studiați următorul desen.

Graficul A arată o corelație pozitivă perfectă între x și y la r = + 1,0. Graficul B - corelația negativă ideală între x și y la r = - 1,0. Graficele C și D sunt exemple de relații mai slabe între variabilele dependente și independente.
Coeficientul de corelație, r, determină atât puterea, cât și direcția relației dintre variabilele dependente și independente. Valorile r variază de la - 1,0 (relație negativă puternică) la + 1,0 (relație pozitivă puternică). Când r = 0 nu există nicio legătură între variabilele x și y.
Putem calcula coeficientul de corelație real folosind următoarea ecuație:

Ei bine! Știu că această ecuație arată ca un amestec înfricoșător de simboluri ciudate, dar înainte de a intra în panică, să aplicăm exemplul unei note la examen. Să presupunem că vreau să determin dacă există o relație între numărul de ore pe care un student le dedică studierii statisticii și scorul final la examen. Tabelul de mai jos ne va ajuta să descompunem această ecuație în mai multe calcule simple și să le facem mai ușor de gestionat.

![]()

După cum puteți vedea, există o corelație pozitivă foarte puternică între numărul de ore dedicate studierii unei discipline și nota la examen. Profesorii vor fi foarte bucuroși să afle despre acest lucru.
Care este beneficiul stabilirii de relații între variabile similare? Mare întrebare. Dacă se constată că există o relație, putem prezice rezultatele examenului pe baza unui anumit număr de ore petrecute studiind subiectul. Mai simplu spus, cu cât conexiunea este mai puternică, cu atât predicția noastră va fi mai precisă.
Utilizarea Excel pentru a calcula coeficienții de corelație
Sunt sigur că, după ce te uiți la aceste calcule teribile ale coeficientului de corelație, vei fi cu adevărat încântat să știi că Excel poate face toată această muncă pentru tine folosind funcția CORREL cu următoarele caracteristici:
CORREL (matrice 1; matrice 2),
matrice 1 = interval de date pentru prima variabilă,
matrice 2 = interval de date pentru a doua variabilă.
De exemplu, figura prezintă funcția CORREL utilizată pentru a calcula coeficientul de corelare pentru exemplul de calificare la examen.