Что дает код страницы в вк. Распаковка и расшифровка скриптов JavaScript
Как изменить код элемента на сайте — для начала нужно узнать в каком файле находится этот код. Есть много способов, но опишу один, наиболее мне приглянувшийся и который использую сам.
Вы можете увидеть код нужного элемента нажав правой кнопкой мыши и исследовать его или посмотреть исходный код страницы. Во всех браузерах аналогичный способ, для каждого существуют определённые дополнения, осуществляющие эти процессы.
Каждому что-то удобно или нет — этот вопрос обсуждать не будем. Наша задача — найти файл с расположенным кодом.
Как найти файл:
Я использую файловый менеджер Total Commander. Нахожу это очень удобным методом.
Итак, например мы нашли элемент, подсветив его в браузере и увидели, что он заключен в <div class =»wpb_wrapper « >
Для начала лучше скопировать папку с вашим сайтом с сервера и расположить её в удобном месте, рабочий стол к примеру.
Копируем <div class =»wpb_wrapper « > и открываем Commander. Выбираем инструменты — поиск
Место поиска — выбираете ранее сохранённую папку с сайтом. Ставите галочку с текстом и вводите искомый
Программа выдаст расположение всех файлов, в которых он присутствует. Как изменить код сайта — вы уже знаете какой файл нужно редактировать.
Если на сервере нет редактора — меняете на компьютере и загружаете по FTP.
Экспериментируйте, сокращайте или увеличивайте запрос — найдётся всё, но не стоит искать динамически подгружаемые данные. Естественно они не покажутся.
Также с помощью браузера изменяются и стили. Подсветили, увидели номер строки, открыли файл стилей и ввели нужное значение. Успехов!
Просматривая бесчисленное множество сайтов в интернете, можно встретить такие, которые очень нам нравятся. Сразу же возникает ряд вопросов. Сайт сделан с помощью самописного кода или какой-нибудь CMS? Какие у него CSS стили? Какие у него мета-теги? И так далее.
Существует много инструментов, с помощью которых можно извлечь информацию о коде страницы сайта. Но под рукой у нас всегда есть правая кнопка мыши. Её-то мы и будем использовать, на примере моего сайта.
Как просмотреть код страницы?
Чтобы посмотреть исходный код страницы сайта, нужно навести курсор мыши на любую область веб-страницы (за исключением изображений и ссылок). После этого нажать на правую кнопку мыши. Перед нами откроется окно с несколькими опциями (в разных браузерах они могут немного отличаться). В браузере Google Chrome, например, это команды:
- назад;
- вперёд;
- перезагрузить;
- сохранить как;
- печать;
- перевести на русский;
- просмотр кода страницы ;
- просмотреть код.
Нам нужно кликнуть на просмотр кода страницы , и перед нами откроется html код страницы сайта.
Просмотр кода страницы: на что обратить внимание?
Итак, Html код страницы представляет собой пронумерованный список строк, каждая из которых несёт информацию о том, как сделан данный сайт. Чтобы быстрей научиться разбираться в этом огромном количестве знаков и специальных символов, нужно различать разные участки кода.
Например, строки кода, находящиеся в внутри тега head содержат информацию для поисковых машин и веб-мастеров. Они не выводятся на сайт. Здесь можно увидеть, по каким ключевым словам продвигается эта страница, как написаны её title и description. Также здесь можно встретить ссылку, перейдя по которой узнаем о семействе google шрифтов, используемых на сайте.
Если сайт сделан на CMS WordPress или Joomla, то это также будет видно здесь. Например, в этой области выводится информация о теме WordPress или шаблоне Joomla сайта. Увидеть её можно, прочитав содержание ссылок, выделенных синим цветом. В одной ссылке виден шаблон сайта.
Например:
//fonts.googleapis.com/css?family=Source+Sans+Pro%3A400%2C400italic%2C600&ver=4.5.3
Мы увидим CSS стили шрифтов страницы. В данном случае используется шрифт. Это видно здесь – font-family: ‘Source Sans Pro’.
Данный сайт оптимизируется с помощью сео-плагина Yoast SEO. Это видно из этого закомментированного участка кода:
This site is optimized with the Yoast SEO plugin v3.4.2 — https://yoast.com/wordpress/plugins/seo/
Вся информация, находящаяся внутри тега body, выводится браузером на экране монитора. Здесь мы видим html код страницы, а в самом низу находится код скрипта Яндекс метрики. Он облечён закомментированным тегом с текстом:
/Yandex.Metrika counter

Подводим итоги
Проведя довольно поверхностный анализ кода главной страницы сайта, можно сделать вывод о том, с помощью каких инструментов сделана эта страница. Мы увидели на ней:
- CMS WordPress;
- Google шрифт Source Sans Pro;
- тема WordPress – Sydney;
- плагины Yoast;
- счётчик Яндекс метрики.
Теперь принцип анализа html кода страницы сайта вполне понятен. Совсем необязательно держать исследуемую страницу открытой в браузере. Сохранить код страницы себе на компьютер можно с помощью комбинаций клавиш ctrl+a, ctrl+c, ctrl+v. Вставьте её в любой текстовый редактор (лучше Notepad++) и сохраните с расширением html. Таким образом, вы в любое время сможете изучить её глубже и найти больше полезной для себя информации.
Эта статья - дополнение к статье про деобфускацию скриптов. Здесь будут рассмотрены основные принципы шифровки и упаковки, слабые места защит, способы ручного снятия, а также универсальные инструменты для автоматического снятия упаковщиков и навесной защиты со скриптов JavaScript. В последнее время все чаще исходный код скриптов шифруется или пакуется. Этим начали увлекаться Яндекс, DLE и другие популярные проекты, а красивые байки про "заботу о пользователях", "экономию трафика" и прочую чушь выглядят очень смешно. Что ж, если кому-то есть что скрывать, значит наша задача вывести их на чистую воду.
Начнем с теории. Из-за особенностей выполнения JavaScript все шифровщики и упаковщики, несмотря на их разнообразие, имеют всего два варианта алгоритма:или как вариант:Второй способ чаще всего используется для защиты исходного html-кода страницы, а также разными троянами для внедрения в страницу вредоносного кода, например скрытого фрейма. Оба алгоритма могут комбинироваться, "навороченность" и запутанность расшифровщика может быть любой, неизменным остается только сам принцип.
В обеих случаях получается, что функциям eval() и document.write() передаются полностью расшифрованные данные. Как их перехватить? Попробуйте заменить eval() на alert() , и в открывшемся MessageBox"е вы сразу увидите расшифрованный текст. Некоторые браузеры позволяют копировать текст из MessageBox"ов, но лучше воспользоваться таким вот полуавтоматическим декодером:
- < html >
- < head >< title > JavaScript Decoder
- < body >
- < script type = "text/javascript" >
- // Функция записи в лог результатов расшифровки
- function decoder (str ) {
- document . getElementById ("decoded" ). value += str + "\n" ;
- < textarea id = "decoded" style = "width:900px; height:500px;" >
- < script type = "text/javascript" >
Для примера возьмем какой-нибудь скрипт с Яндекса, посмотрев исходный код видим что-то нездоровое:
Eval(function(p,a,c,k,e,r){e=function(c){return(c
"".replace(/^/,String)){while(c--)r=k[c]||e(c);k=}];e=function(){return"\w+"};c=1};while(c--)if(k[c])
p=p.replace(new RegExp("\b"+e(c)+"\b","g"),k[c]);return p}("$.1e
.18=8(j){3 k=j["6-9"]||"#6-9";3 l=j["6-L"]||".u-L";3 m=j["6-L-17"]
||"";3 n=j["1d"]||0;$(5).2(".6-9").14("7");$(5).2(".6-9").Z("7",8(
){3 a=$(5).x();3 o=$(5).x();3 h=$(5).B("C");$(5).v("g-4");$(5).16(
$(k).q());3 t=$(o).2("15");3 c=$(o).2(".b-r");3 d=$(o).2(".b-12");
[остальной такой же бред отрезан]
Сразу скажу, что этот скрипт обработан JavaScript Compressor , его легко узнать по сигнатуре - характерному названию фукнции в начале скрипта. Копируем целиком исходный текст скрипта, заменяем первый eval на decoder , вставляем в декодер и сохраняем его как html-страничку.Открываем ее в любом браузере и видим, что в textarea сразу появился распакованный скрипт. Радоваться пока рано, в нем убраны все переносы строчек и форматирование кода. Как с этим бороться написано в статье про деобфускацию .
Второй пример. Вот html-страничка , накрытая программой HTML Protector. Это страница, демонстрирующая возможности программы, поэтому там задействованы все опции: блокировка выделения и копирования текста, запрет правой кнопки мыши, защита картинок, скрытие строки состояния, шифрование html-кода и т.д. Открываем исходный код, смотрим. В самом верху уже знакомый нам document.write и зашифрованный скрипт. Запускаем его через декодер, получаем функцию расшифровки основного содержимого:
Code (JavaScript) :
- hp_ok = true ;function hp_d01 (s ){ ... вырезано ... o = ar . join ("" )+ os ; document . write (o )
Заменяем в функции последний document.write на decoder и вставляем после нее все три оставшихся зашифрованных скрипта:
- < script type = "text/javascript" >
- // Сюда вставить зашифрованный скрипт, предварительно
- // заменить в нем все вызовы eval() и document.write() на decoder().
- hp_ok = true ;function hp_d01 (s ){ .... o = ar . join ("" )+ os ; decoder (o );
- hp_d01 (unescape (">QAPKRV%22NCLEWC ....
- hp_d01 (unescape (">QAPKRV%22NCLEWCEG? HctcQa ...
- hp_d01 (unescape (">`mf{%22`eamnmp? !DDDDDD %22v ...
Для удобства в статье скрипты приводятся не полностью, вы же должны копировать их целиком. Открываем декодер в браузере и видим защитные скрипты, добавленные программой, и расшифрованный исходный текст страницы. Для удобства можно расшифровывать только третий скрипт, в котором содержится html-код страницы. Вот и вся защита. Как видите, ничего сложного. Аналогично снимаются и другие защиты html-страниц.
От ручной расшифровки перейдем к автоматической. Для снятия защит первого типа я немного модифицировал уже известный вам скрипт Beautify Javascript и откомпилировал его в exe-файл. Он без проблем справляется с большинством виденных мной защит и упаковщиков JavaScript.
Eval.JavaScript.Unpacker.1.1-PCL.rar (12,124 bytes)
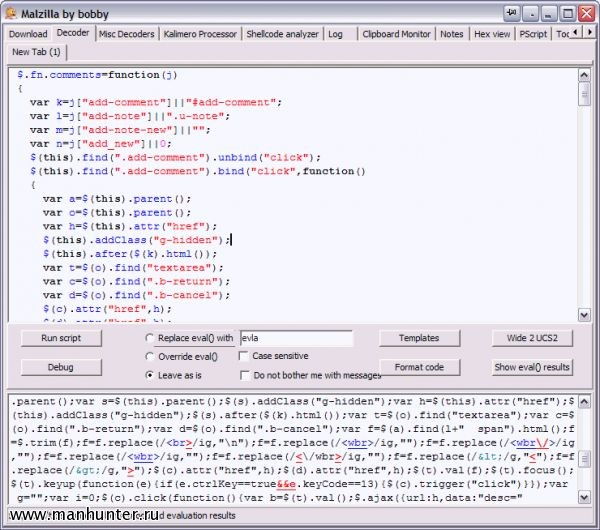
Для более сложных случаев придется пускать в ход тяжелую артиллерию. Это бесплатный проект , предназначенный для исследования троянов и другого вредоносного кода. Поскольку все программы, предназначенные для защиты авторского права, являются однозначно вредоносными, Malzilla поможет нам в борьбе с ними. Качаем (на сегодняшний день это 1.2.0), распаковываем, запускаем. Открываем вторую вкладку Decoder, в верхнее окно вставляем код зашифрованного скрипта, нажимаем кнопочку Run script .

В папке eval_temp складываются все результаты выполнения функций eval(), в том числе и промежуточные. Их можно посмотреть, нажав на кнопку Show eval() results , текст откроется в нижнем окне. Его можно скопировать, вставить в верхнее окно и сразу же отформатировать нажатием кнопки Format code . Кроме декодера Malzilla имеет еще множество инструментов и настроек, позволяющих легко снять любую защиту со скриптов JavaScript.
Также можно обратить внимание на еще один бесплатный инструмент для работы с зашифрованными скриптами - FreShow . Функций в нем поменьше, но вполне имеет место быть. С офсайта можно скачать демонстрационный ролик, показывающий пример работы с программой.
Как видите, нет ничего сложного в снятии защиты со скриптов JavaScript и с html-страниц. Вы все еще продолжаете защищать свои поганые "аффтарские права"? Тогда мы идем к вам!
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Исходный код сайта – это совокупность HTML-разметки, CSS стилей и скриптов JavaScript, которые браузер получает от веб-сервера.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
Его можно сравнить с набором команд, которые дает солдатам командир. Представьте, что зрители не видят и не слышат начальника. С их точки зрения военные самостоятельно выполняют действия. В нашем случае командир – это браузер, команды – это исходный код, а марширующие солдаты – это конечный результат.
Хранится сайт на веб-сервере, который отправляет страницу по запросу пользователя. Запрос – это ввод URL в строке адреса, щелчок по ссылке или нажатие на кнопку отправки данных в форме. Не важно, на каком языке написаны веб-страницы, включают ли они программную часть. Конечным результатом работы любого серверного алгоритма является набор html-тегов и текста.
Исходный код страницы – это набор данных, включающий в себя:
- html-разметку;
- стилевую таблицу или ссылку на файл ;
- программы, написанные на JavaScript или ссылки на файлы с кодом.
Эти три раздела обрабатываются браузером. Для сервера это просто текст, который необходимо отправить в ответ на запрос.
Зачем нам может понадобиться изучать исходный код
Все, что мы увидим, мы сможем проанализировать и применить для решения тех или иных задач, которые возникают в ходе работы с сайтом, особенно при его оптимизации. Просмотрев исходный код, мы можем:
- Увидеть мета-теги своего или чужого сайта для их анализа.
- Увидеть наличие или отсутствие некоторых элементов на сайте: счетчиков, кодов идентификации в различных системах, определенных скриптов и прочего.
- Узнать параметры элементов: размеры, цвета, шрифты.
- Найти путь к фотографиям и другим элементам, располагающимся на странице.
- Изучить ссылки со страницы.
- Найти проблемы с кодом, мешающие в процессе оптимизации сайта: невынесенные в отдельные файлы стили, скрипты, невалидный код.
Это основные возможности, но на самом деле, умея читать код, вы сможете узнать о странице намного больше.
Как посмотреть исходный код сайта
Полностью в том виде, в каком он выложен на сервере, из браузера это сделать не удастся. А вот увидеть всю разметку можно, нажав на странице правую кнопку мыши. Здесь и далее на примере Google Chrome.

Выбираем опцию «Просмотр кода страницы» и получаем полный листинг в отдельной вкладке.

Это просто текст, который придется анализировать, чтобы понять. А вот получить интерактивный код можно с помощью инструментов разработчика.
Как найти исходный код страницы сайта
Нажимаем на значок меню в браузере. Чаще всего он находится справа и имеет вид трех точек или полосок.

В разделе дополнительных инструментов выбираем «Инструменты разработчика».

Откроется окно, в котором отображается активное состояние кода. Это значит, что при щелчке мыши на разметке рядом отобразится стиль элемента, а на странице будут подсвечиваться выбранные блоки.

Во вкладке «Source» можно просмотреть содержимое некоторых файлов: скрипты, шрифты, изображения.


Во вкладке «Security» доступна проверка сертификата сайта.

Вкладка «Audits» поможет провести проверку выложенного на хостинг ресурса.

Если расположение панели справа неудобно, можно нажать три точки и поменять его, выбрав желаемый пункт.

Как посмотреть мета-теги
Каждый html-документ включает в себя теги структуры. Вот некоторые из них:
- Html – весь документ.
- Head – раздел служебных заголовков.
- Title – заголовок страницы (отображается на вкладке).
- Body – тело документа.
- H1-H6 – заголовки текста страницы.
- Article – статья.
- Section – раздел.
- Menu – меню.
- Div – блок.
- Span – строка.
- P – абзац.
- Table – таблица.
Элементы предназначены для логического разграничения разделов на странице, при необходимости они оформляются с помощью стилей. В них размещается текст, который так или иначе виден на странице. Но в теге Head присутствует служебная информация. Для ее указания служат мета-теги. Все что в них записано, предназначено для сервера и поисковых систем.

Их содержимое другим способом узнать невозможно.
Обратим внимание на тег Link. С его помощью указываются ссылки на внешние подключаемые файлы. При желании можно увидеть содержимое и сохранить на диск. Для этого наведите указатель на адрес и нажмите ПКМ. Выберите пункт «Open in new Tab».

В новой вкладке откроется указанный файл, который можно просмотреть или сохранить.
Как посмотреть исходный код страницы для отладки скрипта
В этом случае удобнее всего открывать страницу на локальной машине. Если необходимо только исправить разметку, стили и скрипты, то это можно делать прямо из папки. Html-код просматривается таким же образом. А вот ошибки кода JavaScript можно увидеть во вкладке «Console». Здесь показывает описание ошибки и номер строки, в которой она возникла.

Синтаксическую можно увидеть непосредственно в коде. Для этого предназначена вкладка «Source».

Как посмотреть код конкретного элемента
Для больших страниц с большим количеством элементов сложно найти нужный код во всей разметке. В таком случае следует воспользоваться специальной командой контекстного меню. Наведем мышь на фрагмент и нажмем ПКМ. Выберем команду «Просмотреть код».

Откроется то же окно, но с фокусировкой на выбранном объекте.

Резюме
Мы рассказали, что такое исходный код страницы. Достаточно освоить элементарные знания HTML и CSS, и пользуясь удобными инструментами разработчика, вы сможете проводить отладку своих собственных html-документов.
Просмотр кода ресурсов в интернете позволит вам учиться не только на собственном опыте, но и использовать реальные рабочие примеры. А для seo-специалистов будут полезны мета-теги, информация в которых может сказать о сайте многое.


